
Amazon DynamoDBのNextTokenを使ったページネーションの挙動を調査した
2019.06.22
はじめに
データベースにDynamoDBを使ってアプリケーション開発を行っているときに、クエリ結果を複数ページに分けて取得するページング/ページネーション処理を実装する必要が出てきた。
DynamoDBでは、結果が複数ページに分かれる際にはレスポンスの中に次ページの情報を表す文字列(NextToken)が返ってくるので、それを使って次のページのリクエストを再度発行すればよい。
しかし、1ページ目に当たるデータを取得した後にDynamoDBテーブル上のデータが増減した場合、1ページ目の結果と共に返されたNextToken を使って2ページ目のクエリを行うとどのような結果が返るのかという疑問に至った。
そこで、シンプルなテストデータを挿入しつつAWS CLIからクエリを実行して検証してみた。
DynamoDBテーブルを作ってテストデータを入れる
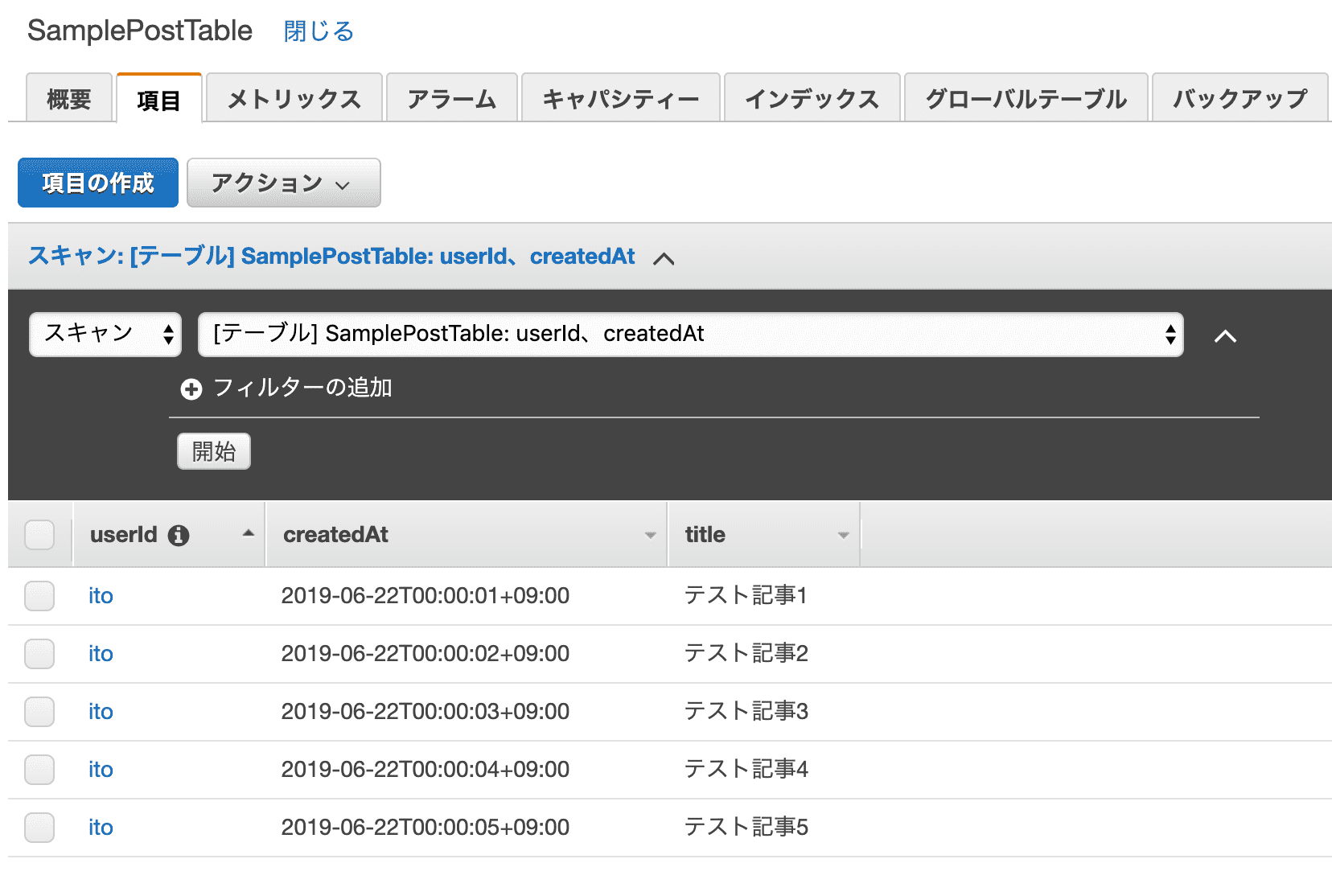
検証のためにDynamoDBに SamplePostTable という名前のテーブルを作った。
設定は以下の通り。
- オンデマンドモード
- Hash Key:userId
- Sort Key:createdAt
ユーザーが投稿できるアプリケーションをイメージしてみた。
このテーブルに10個ほどデータを入れて検証しようと思ったが、マネジメントコンソールから一つずつデータを入れていくのは大変なので、nori3tsu/dynamodb-seed を使わせていただくことにした。
# インストール
$ npm i -g dynamodb-seedテストデータはYAMLで記述できるようなので、以下のような seed.yaml を作ってみた。
Seeds:
-
TableName: SamplePostTable
Key:
- userId
- createdAt
Items:
-
userId: ito
createdAt: '2019-06-22T00:00:01+09:00'
title: テスト記事1
-
userId: ito
createdAt: '2019-06-22T00:00:02+09:00'
title: テスト記事2
-
userId: ito
createdAt: '2019-06-22T00:00:03+09:00'
title: テスト記事3
-
userId: ito
createdAt: '2019-06-22T00:00:04+09:00'
title: テスト記事4
-
userId: ito
createdAt: '2019-06-22T00:00:05+09:00'
title: テスト記事5コマンドを実行して挿入。
$ dynamodb-seed -f seed.yamlこれだけでDynamoDBのテーブルに5件のデータを一発で入れることができた。
AWS CLIを使ってQueryを実行してみる
Hash Keyの条件だけ指定してQueryを実行してみる。
$ aws dynamodb query --table-name SamplePostTable \
--key-conditions '{
"userId":{
"ComparisonOperator": "EQ",
"AttributeValueList": [{ "S": "ito" }]
}
}' \
--max-items 2実行結果
{
"Count": 5,
"Items": [
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:01+09:00"
},
"title": {
"S": "テスト記事1"
}
},
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:02+09:00"
},
"title": {
"S": "テスト記事2"
}
}
],
"NextToken": "eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDJ9",
"ScannedCount": 5,
"ConsumedCapacity": null
}5件あるデータを2件取得したため、2ページ目にアクセスするための NextToken が含まれている。
これを使って2ページ目のデータを取得してみる。
$ aws dynamodb query --table-name SamplePostTable \
--key-conditions '{
"userId":{
"ComparisonOperator": "EQ",
"AttributeValueList": [{ "S": "ito" }]
}
}' \
--max-items 2 \
--starting-token eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDJ9実行結果
{
"Count": 0,
"Items": [
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:03+09:00"
},
"title": {
"S": "テスト記事3"
}
},
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:04+09:00"
},
"title": {
"S": "テスト記事4"
}
}
],
"NextToken": "eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDR9",
"ScannedCount": 0,
"ConsumedCapacity": null
}確かに最初に取得できた2件をスキップして次の2件が得られている。
NextTokenを手に入れてたあとにレコード数が変わった場合の動作
ある時点でQueryを実行して手に入った NextToken を使って2ページ目を取得しようとしたときに、レコードが増減していたらどうなるのだろうか。
以下のようなデータを2件ずつ取ろうと思ってQueryを実行して、Item3からアクセスできる NextToken が手に入ったとする。
・Item1
・Item2
・Item3(NextToken = XXXX)
・Item4ところが、 NextToken を使ってアクセスしようとしたときには既にデータが更新されていたとする。
・Item0(これが追加された)
・Item1
・Item2
・Item3
・Item4なお、一番後ろに追加されてしまうと挙動が検証できないので、Sort Keyを設定した上で先頭に入るような更新操作をするものとする。
Queryを実行しているクライアントからはシンプルに続きのデータが欲しいので、 NextToken を渡したらItem3とItem4が帰ってきて欲しい。
ないと思うが、 NextToken に格納されている情報が「先頭から3番目」という内容だったらItem2とItem3が取得されてしまい、最初に実行したQueryの結果と重複した項目が手に入ってしまう。
高速に書き込みがあるテーブルだと、Query結果が丸ごと重複する可能性もあって非常に使いづらい。
そんなことはないはずなので実際はどうか検証してみる。
先ほどの検証で、1回目のQueryと2回目のQueryの間にレコードの増減がないときは問題なくページネーションが実現できることが確認できた。
次の検証は以下のフローで行う。
- 1回目のQueryを実行する(「テスト記事1」と「テスト記事2」が取得できるはず)
- 1回目のQueryの後に
createdAtが一番古い「テスト記事0」をマネジメントコンソールから入れてみる - 1回目のQueryで手に入った
NextTokenを使って2回目のQueryを実行してみる - 「テスト記事3」と「テスト記事4」が取得できればうれしい
実行結果はなんと、
{
"Count": 0,
"Items": [
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:02+09:00"
},
"title": {
"S": "テスト記事2"
}
},
{
"userId": {
"S": "ito"
},
"createdAt": {
"S": "2019-06-22T00:00:03+09:00"
},
"title": {
"S": "テスト記事3"
}
}
],
"NextToken": "eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDR9",
"ScannedCount": 0,
"ConsumedCapacity": null
}で、「これじゃ厳しくない?」と思っていた挙動になってしまった。
時系列データを順番に取得するときはNextTokenを使わない方がいいかもしれない
SNSのタイムラインのような、時系列でソートされたデータを順番に取得するときは、
- 1回目のQuery結果に含まれる
NextTokenを使って2ページ目を読み込む
という設計ではなく、
- 1回目のQuery結果に含まれる最後のアイテムのSort Key属性を渡して次のデータを読み込む
という設計にした方が良さそう。
まとめ
思っていた挙動とは違う動作になってしまったので、AWS Loft Tokyoに行ったときにAsk An Expertブースで質問しようと思う。
この NextToken を使ったパターンには自分がまだ知らない仕様や使い方があるのかもしれない。