
Amazon SageMakerで手書き文字を判別!AWS Loft Tokyo Code Happy Hour参加レポート
2019.06.28
Code Happy Hour
目黒にあるAWS Loft Tokyoで月1〜隔月で開催されているラフなイベント「Code Happy Hour」に参加してきた。
参加者は20名程度で、コミュニケーションがしっかり取れるくらいの人数でちょうどよかった。
今回はStartup SAで機械学習に強い針原さんがSageMakerのハンズオンを行なってくださるとのことだったので、それ目当てで参加。
AWS Startup SAsによるLT
1. Amazon Cognito User Poolsの利用で、既存のサービスDBとの統合や使い分けをどうするとよいのか by 松田さん
-
Cognito User Pool
- 数百万ユーザーまでスケールする認証基盤
- 認証周りの負荷をオフロードすることができる
- Cognitoで認証して得られたJWT Tokenを添えてAPI Gatewayにリクエストできる
-
Cognitoに住所・趣味・乗っている車などなど登録できるんじゃないか?という質問をよく受ける
- 頻繁にアクセスするデータ、柔軟なクエリで参照したいデータはサービス側のDBに持たせた方がより柔軟性の高い設計になる
- 認証に必要な情報だけCognitoに持たせるとよい
- IDトークンには属性情報も含まれているので、それを使うことも検討する
-
Cognitoを叩くときにSDKを使うべきか?
- SRPプロトコルを使った認証をする必要があって大変なので、SDKを使うのが便利
- Androidアプリでメソッド数の上限がありSDKを入れたくないという場合は自分で書くことを推奨することもある
2. Train, Be Happy! by 針原さん
-
Amazon RDSに溜めているデータをAmazon S3に持っていきたいがどうしたらよいか?
- AWS Database Migration Service(DMS)を使う
- AWS Glueを使う
- データ変換のETLとかができるサービス
-
ELBのログをPV集計等に使いたい。どのような基盤でログ分析をしたらよいか?
- ElasticSearch/Logstash/Kibanaを使ってるならそれに投げ込んでKibanaで分析
- S3に溜めといてAthenaなどを使うのもあり
-
1分ごと定期実行オブを動かしたいがどうしたらよいか?
- Step Functionsでジョブを定義して、Step FunctionsのAPI経由で定期的にジョブ実行する
- Lambdaを設定して、API Gateway経由で定期的にキックする
- これらをCloudWatch Eventsでキックする
- SageMakerも定期的にトレーニングのジョブを回す必要がある
- 全体のフローをStep Functionsでつなぐのはあり
-
aws-samplesリポジトリ
- AWSのサンプルが雑多においてあるアカウント
-
Lambdaで15分以上のジョブを実行したい場合はどうする?
- コンテナの利用がオススメ
Amazon SageMakerハンズオン

成果物
Amazon SageMakerでJupyter Notebookのインスタンスを立ち上げて、aws-samplesリポジトリにあるchainer_mnistを試した。
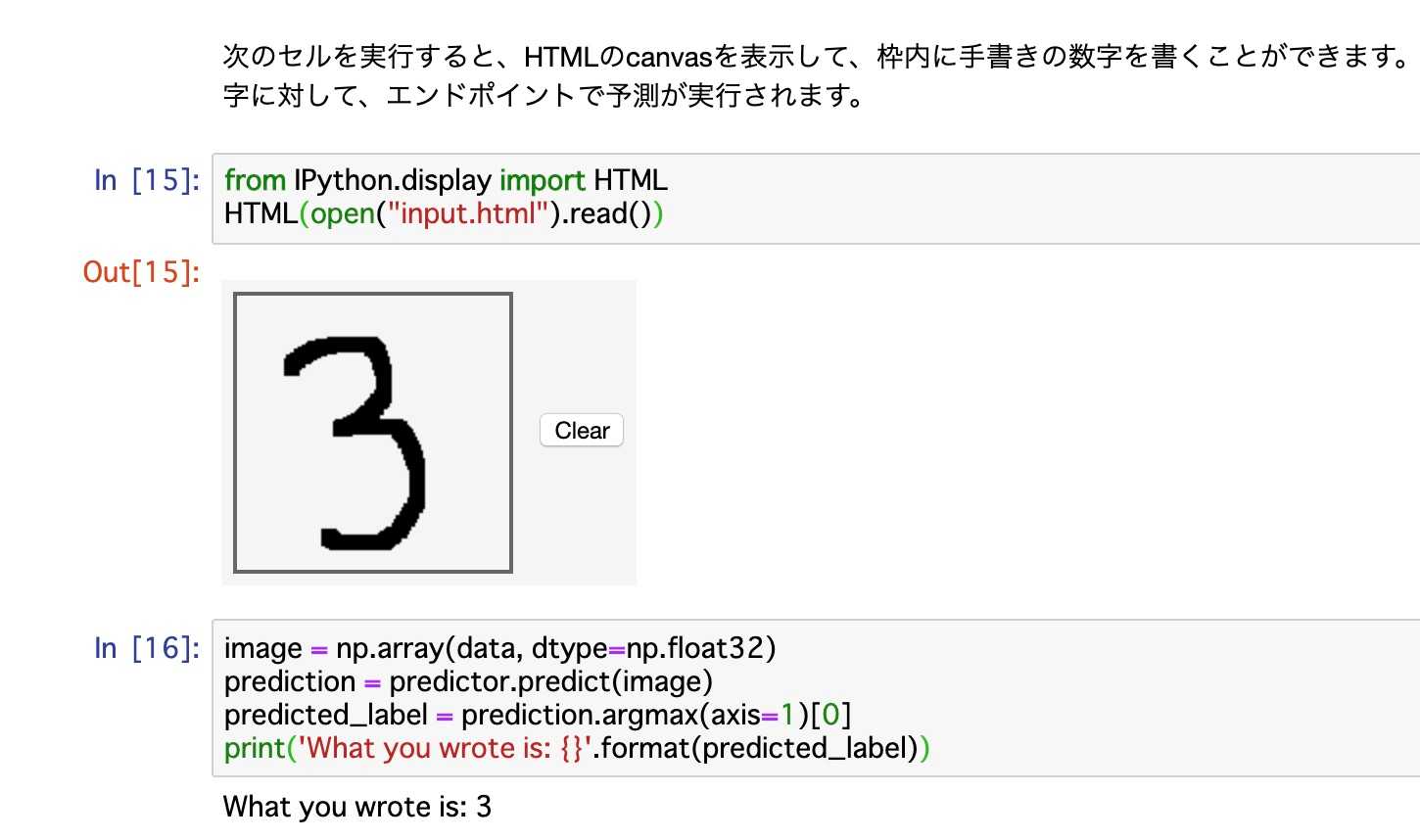
手書き入力した数字を判別できるAPIを作成できた。
内容
-
P系のインスタンスにGPUが載っている
-
モデルのトレーニングにP3インスタンスを、推論にC5インスタンスを使うとかがよくある
-
学習
- モデルを賢くするための訓練のこと
- 正解のデータをはじめに用意しておく必要がある
-
推論
- 賢くしたモデルを使う
-
機械学習には教師あり学習と教師なし学習がある
-
機械学習の最初に取り組みやすいのがMNISTを使った数字の認識
-
Jupyter Notebook
- Pythonをインタラクティブに実行したいときに使うツール
-
開発と学習の環境を分ける
- 学習はGPUをぶん回す
- GPUは単価が高い
- SageMakerはトレーニングをするときだけGPUを立てることができる
-
SageMakerのインスタンスタイプは
ml.* -
ml.p3.2xlargeを使えば基本十分
-
SageMakerには専用のSDKがある
-
普通のAWS SDKはデータサイエンティストが慣れ親しんでいないインターフェースだが、SageMaker SDKはデータサイエンティストが慣れ親しんでいるようなインターフェースで作られている
- pipでインストールできる
- pip install sagemaker
- SageMakerで立ち上がるインスタンスにはデフォルトで入ってる
-
インスタンスを立ち上げる際にIAMロールも指定する
- トレーニング用のノードがS3を読む必要があるのでロールを指定する必要がある
- SageMakerのインスタンスにひっついてるロールを渡せる
-
拡張子ipynb
- Jupyter上で実行できるファイル
-
シーケンシャルなニューラルネット
- nn.Sequential()
-
ベーシックなネットワーク
- ノード間が全て繋がっていて、3層以上あるもの
-
trainとtest
- 学習に使ったデータとは別のデータを使ってテストする
- モデルの精度を検証する
-
モデルのアップデートの手法もいろいろある
- sgd:一番ベーシックな方法
- 程よいノイズを与えながら一番誤差が少なくなるようにする方法
-
epocs
- トレーニングのステップ
- 10〜100とか
-
net関数
- net(data)
- ネットワークに画像をインプットする
-
loss関数
- ズレを知る
-
L.backward
- 順方向に伝播した結果をもとに、逆方向に重みのアップデートする
- Back Propagationと呼ぶ
-
過学習
- 学習したデータセットに対しては精度が高いのに、それ以外のデータを入れると途端に精度が悪くなる現象
- 見たことないデータでもいい感じに精度を出せるようにチェックする必要がある
-
1 epochの計算も一瞬では終わらない
-
Chainer
-
Chainerのデータセットは画像とラベルのタプルになってる
-
扱いやすくするためにばらす
-
変数train_imagesに画像の行列が配列で入っている
-
変数train_labelsに正解の数字が配列で入っている
-
-
Jupyter Notebookでは最後の行の評価結果は自動で出力される
-
ハイパーパラメーター
- モデルをトレーニングすると重みが出てくるが、ニューラルネットワークの設計自体は変わらない
- レイヤーは何層がいいのか
- モデルのアップデートの方法はどれが良いのか
- ニューラルネットワークの設計もトレーニングとは別に調整する必要がある
- ハイパーパラメーターチューニング
- 色々なパラメーターで試してみて、結果を比べる作業を行う
-
Amazon Rekognitionは複数のモデルを組み合わせて高い精度を出しているので、Amazon SageMaker Neoを使ったエッジデバイスでの機械学習では替えがきかない(精度が高くならない)
質問
-
GPUインスタンスはどこに立ち上がる?マネコンからみれる?
- マネジメントコンソールの「トレーニングジョブ」のメニューの中に並ぶので見ることができる。
-
HTTPのAPIを立てるときに、Jupyter Notebookを開いて
tuner.deploy()を叩くのは不安定に感じる- マネジメントコンソールの「エンドポイント設定」から作ることもできる。
-
SageMaker単体でHTTPエンドポイントを立ち上げられるのに、前段にAPI GatewayとLambdaを配置する必要はある?
- 入力値の調整をすることができる
-
「モデルを作る」というが、モデルの実態はどのような形式なのか?
- フレームワークによって形式が色々ある
- ニューラルネットワークの構造を表すJSONファイル
- ネットワークのノード間の結合の重みを示すPythonのArrayファイル
-
モデルのトレーニング中にJupyter Notebookインスタンスを停止・削除したらどうなる?
- トレーニングは実行され続ける
- マネジメントコンソールから終了することができる
-
安全な後片付けの方法を知りたい
- Jupyter Notebookのインスタンスを停止・削除する
- 停止だけではEBSの課金が発生する
- HTTPエンドポイントを削除する
- S3バケットも適宜削除する
-
train()関数の実行が時間がかかるからGPUにやらせようってことなのか?train()関数の中のループの回数が多いのはもちろん、モデルの学習の際に行列の演算を大量に行う。GPUは行列の演算に強いため、高速に計算できる
感想
機械学習は「いつかやりたい」と思っていてなかなか手を出せていなかったので、このようなハンズオンでサクッと試すことができてよかった。基本的な知識が全くなかったのでとりあえずAWS Black BeltセミナーのAmazon SageMaker Basic SessionとAmazon SageMaker Advanced Sessionを見ておいたが、それでもついていくのがやっとだった。
AWSが提供している機械学習系サービスでは、Amazon RekognitionやAmazon Textractのようなマネージド型のサービスもあるので、そちらも触りつつ機械学習の可能性を探っていきたい。